
In this tutorial, you will learn how to scrape LinkedIn user profiles, job postings, and company pages with Python and Selenium library. As well as you will also understand how to create a script for login on LinkedIn.
To scrape LinkedIn pages, you first need to install the Selenium library for Python. You can install it by executing the following command in your terminal.
pip install selenium
You will also need a Webdriver to open the browser in Selenium. You can easily download and install Chrome Webdriver by following the article How to Install Chrome WebDriver in Selenium Python.
Table of contents
- Import all required libraries
- Create Webdriver for Chrome
- Script for Logging in to LinkedIn
- Scrape data from the user profiles
- Scrape data from the company page
- Scrape data from the Job Posting page
- Challenge
1. Import all required libraries
First, you need to import all required libraries to build our Selenium script. Create a new Python file with the name linkedin_scraper.py and open it in your favorite editor. Simply copy and paste the below code into your newly created Python file. As well as add if __name__ == "__main__": idiom to create an entry point for your script as shown below.
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
if __name__ == "__main__":
2. Create Webdriver for Chrome
To open the LinkedIn website, you will need chromedriver. Simply copy and paste the below code into your Python file. This code is designed to launch a new Chrome browser. Additionally, ensure that you change the chromedriver path accordingly.
if __name__ == "__main__":
driver = webdriver.Chrome(service=Service(r"your chromedriver path"))
3. Script for Logging in to LinkedIn
The next step is logging in to your LinkedIn account using your credentials. In this step, you will understand how to inspect elements and identify the HTML tags for the username, password, and Sign in fields.
To begin, open the LinkedIn login page by navigating to the URL https://www.linkedin.com/login. To find the HTML tags for the username field, simply right-click on the username field and select the Inspect option from the menu that appears.
Below is an image highlighting the HTML code for the username input tag.
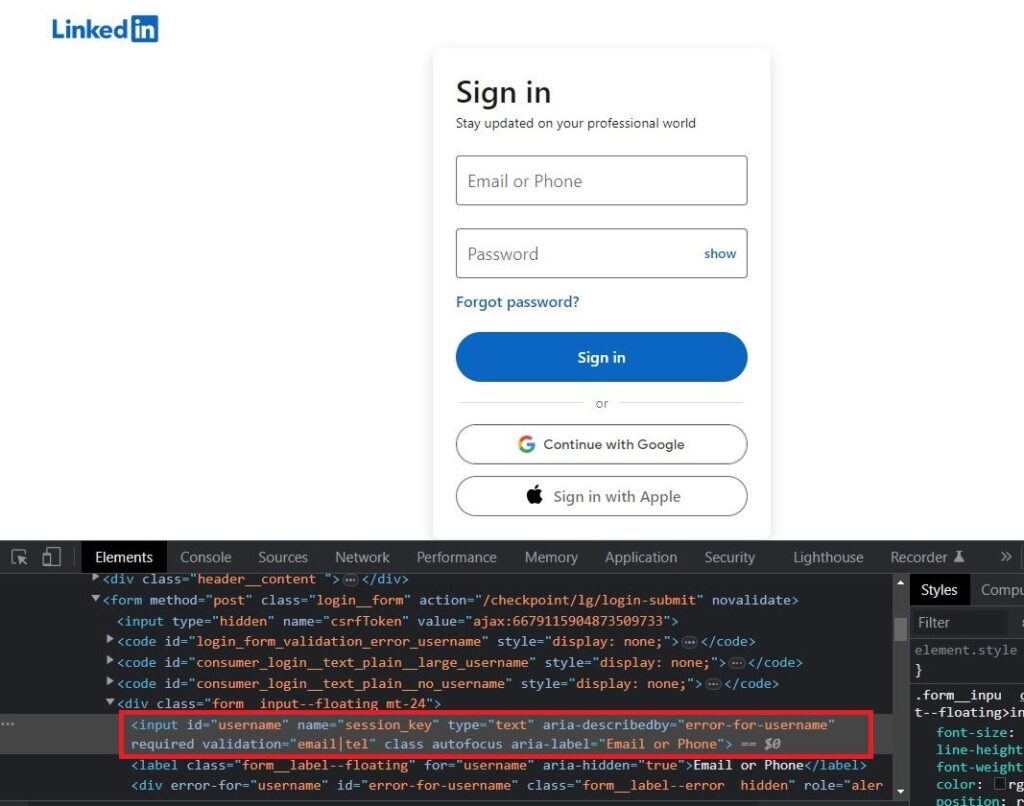
From the highlighted HTML code, you can observe that the username field has an attribute id="username". We can use this attribute to create the code for the username field. Subsequently, you will need to input your username using the send_keys() method provided by Selenium.
Create a Selenium code for the username field
Below is the Python code for the username field as well as inputting the username text in this field:
username_field = driver.find_element(By.ID, "username")
username_field.send_keys("your username")
Create a Selenium code for the password field
We can follow the same steps to create a password field. The password has an attribute id="password" and the Python code to access and input the password in this field is:
password_field = driver.find_element(By.ID, "password")
password_field.send_keys("your password")
Create a Selenium code for clicking the Sign in button
Once you have entered your username and password, the next step is to click on the Sign In button. You can generate the code for this action by following the same steps we before used for the username and password fields. Then, using Selenium, you will need to invoke the click() method to simulate a button click.
sign_in_btn = driver.find_element(By.CSS_SELECTOR, "button[type='submit']")
sign_in_btn.click()
The complete code for Logging in is given below:
--snip—
if __name__ == "__main__":
driver = webdriver.Chrome(service=Service(r"C:\ChromeDriver\chromedriver.exe"))
username_field = driver.find_element(By.ID, "username")
username_field.send_keys("your username")
password_field = driver.find_element(By.ID, "password")
password_field.send_keys("your password")
sign_in_btn = driver.find_element(By.CSS_SELECTOR, "button[type='submit']")
sign_in_btn.click()
When you run the above code, the selenium will use the login credentials provided in the code and click on the Sign in button to login to LinkedIn.
4. Scrape data from the user profiles
Once you have logged into your LinkedIn account, you can use Selenium code to extract user profiles. For example, let’s consider scrapping the Name, Title, Location, and Email fields from the profile located at https://www.linkedin.com/in/veekekv-chuhna-077aa0126/. Feel free to choose any profile for extracting these details.
To proceed, open the given profile URL in your browser and inspect the elements by right-clicking on the required fields, as shown in the image below.
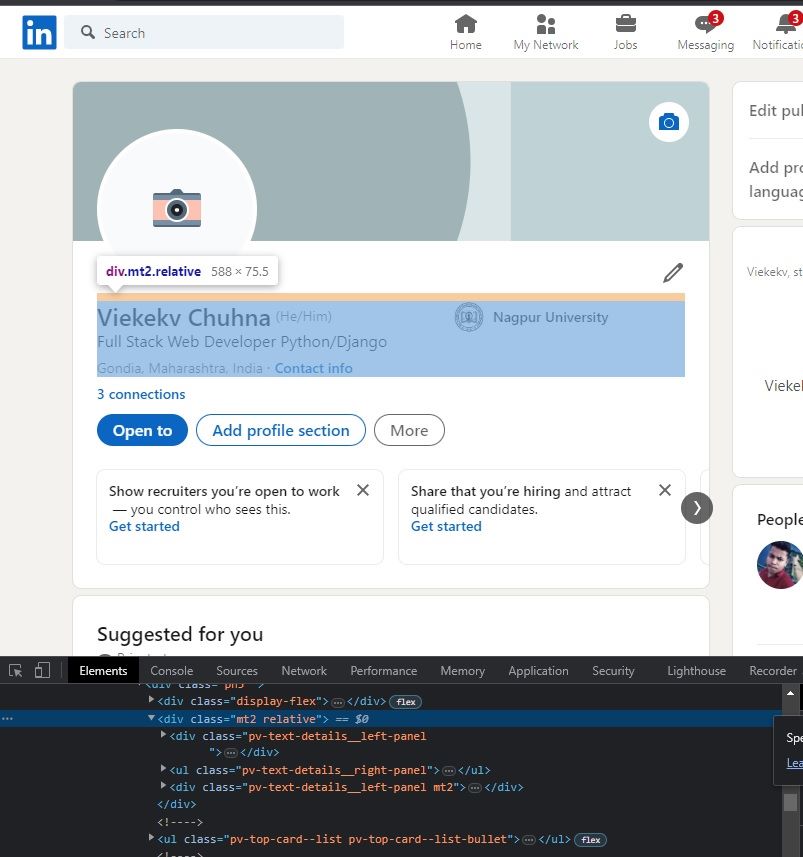
A. Scraping user name
When you inspect the user profile name element shown on the webpage, you will notice below HTML code:
<h1 class="text-heading-xlarge inline t-24 v-align-middle break-words">Veekekv Chuhna</h1>
The selenium code to extract the name from this HTML tag is:
profile_name = driver.find_element(By.CSS_SELECTOR, "h1.text-heading-xlarge").get_attribute("innerText")
B. Scraping user title
To scrape the user profile title, right-click on the title field and click on inspect the menu. The HTML tag for the profile title is:
<div class="text-body-medium break-words>Full Stack Web Developer Python/Django</div>
The selenium code to extract the profile title from this HTML tag is:
profile_title = driver.find_element(By.CSS_SELECTOR, "div.text-body-medium").get_attribute("innerText")
C. Scraping user location
Follow the same step to get HTML for the user profile location. You will get the HTML code:
<span class="text-body-small inline t-black--light break-words">Gondia, Maharashtra, India</span>
The selenium code to extract profile location from this HTML tag is:
profile_location = driver.find_element(By.CSS_SELECTOR, "span.text-body-small.inline").get_attribute("innerText")
D. Scraping user email
The email of the profile is hidden in the Contact Info section. To scrape user profile email, we need to click on the Contact Info link. After clicking, you can see the below page:
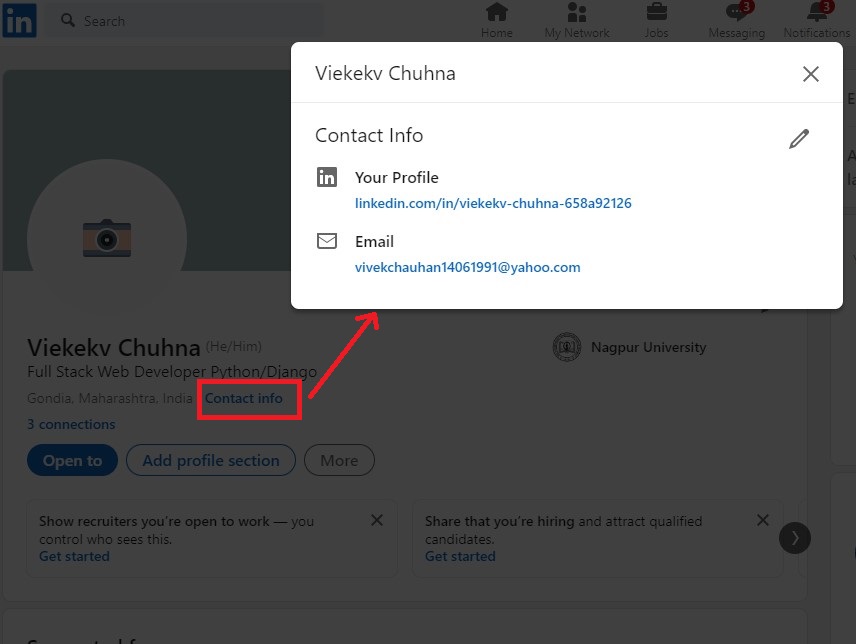
Note: The Email field will only be visible if the profile user has chosen to make it public or if you have a first-degree connection with the profile.
You can get HTML code for the email field by following the same steps mentioned above. The HTML code for the email field is:
<a href="mailto:vivekchauhan14061991@yahoo.com" class="pv-contact-info__contact-link link-without-visited-state t-14" target="_blank" rel="noopener noreferrer">vivekchauhan14061991@yahoo.com</a>
The Python code to click on the Contact Info link and extract email using the above HTML tag is:
# Click on Contact Info link
driver.find_element(By.ID, "top-card-text-details-contact-info").click()
time.sleep(1)
profile_email = driver.find_element(By.CSS_SELECTOR, "a.pv-contact-info__contact-link[href^='mailto:']").get_attribute("innerText")
E. Final code to scrape user profiles
To enable the scraping of any number of profiles, we need to change the existing code. To do this, create a function that accepts the driver and profile URL as parameters, allowing us to scrape all the necessary fields.
Create a new function named scrape_profile(driver, profile_url) and paste the above code snippet. Your file will then appear as follows:
def scrape_profile(driver, profile_url):
"""Scrape required fields from LinkedIn URL"""
driver.get(profile_url)
profile_name = driver.find_element(By.CSS_SELECTOR, "h1.text-heading-xlarge").get_attribute("innerText")
profile_title = driver.find_element(By.CSS_SELECTOR, "div.text-body-medium").get_attribute("innerText")
profile_location = driver.find_element(By.CSS_SELECTOR, "span.text-body-small.inline").get_attribute("innerText")
# Click on Contact Info link
driver.find_element(By.ID, "top-card-text-details-contact-info").click()
time.sleep(1)
profile_email = driver.find_element(By.CSS_SELECTOR, "a.pv-contact-info__contact-link[href^='mailto:']").get_attribute("innerText")
print("Profile Name: {}".format(profile_name))
print("Title: {}".format(profile_title))
print("Location: {}".format(profile_location))
print("Email: {}".format(profile_email))
You can call this function from the main block using this function name by passing driver and profile_url.
For example,
scrape_profile(driver, "https://www.linkedin.com/in/veekekv-chuhna-077aa0126/")
As well as you can change your code such that it will scrape data from more than one profile URL by placing the above function inside the loop.
5. Scrape data from the company page
Now, let’s begin building the script to scrape LinkedIn company data. Our target URL for data extraction will be https://www.linkedin.com/company/microsoft/.
We will extract the company name, industry, location, and website URL. Although it’s possible to scrape more details, we will focus on these key fields for simplicity.
To start, you need to click on the About tab on the company page. This can be achieved by appending the text “about/” to the URL. The corresponding Python code is as follows:
driver.get(company_url + "about/")
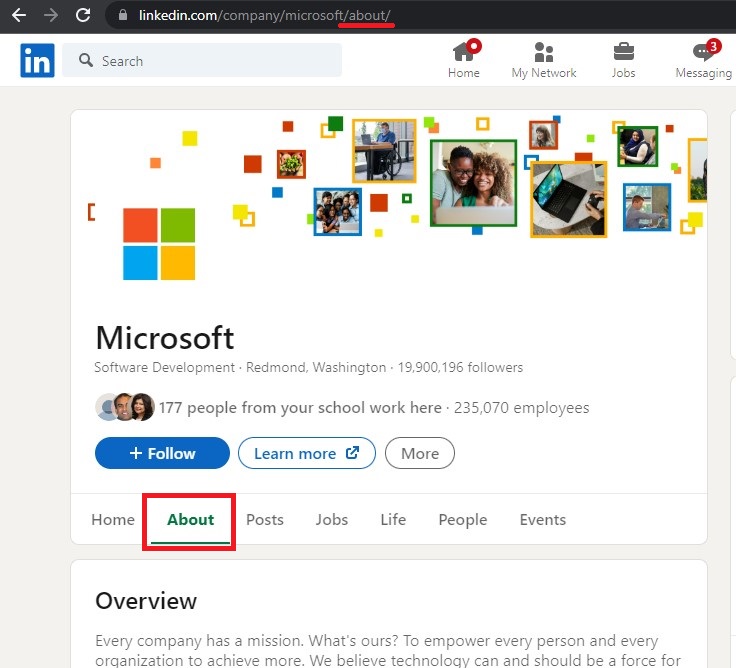
Now that we have navigated to the company’s About page, let’s examine the HTML tags associated with the fields we need to scrape.
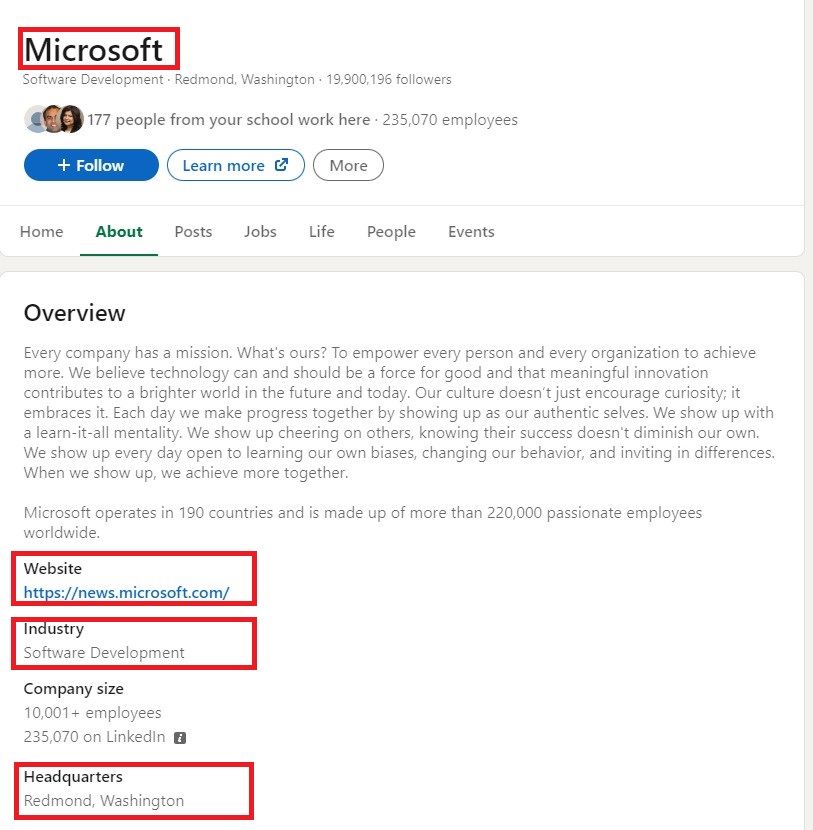
Let’s scrape these fields one by one.
A. Scraping company name
The company name can scrape by simply checking its HTML tag name using inspect element. The HTML tag for the company name is:
<h1 id="ember413" class="ember-view text-display-medium-bold org-top-card-summary__title
full-width " title="Microsoft">
<span dir="ltr">Microsoft</span>
</h1>
The Selenium code to extract the company name using the above HTML code is:
company_name = driver.find_element(By.CSS_SELECTOR, "h1 span").get_attribute("innerText")
B. Scraping industry, location, and website URL
To extract the company’s website, industry, and headquarters location, you need to inspect these elements. You will observe that they are all contained within a <section> container with the HTML tag as shown in the image below.
<section class="artdeco-card org-page-details-module__card-spacing artdeco-card org-about-module__margin-bottom">
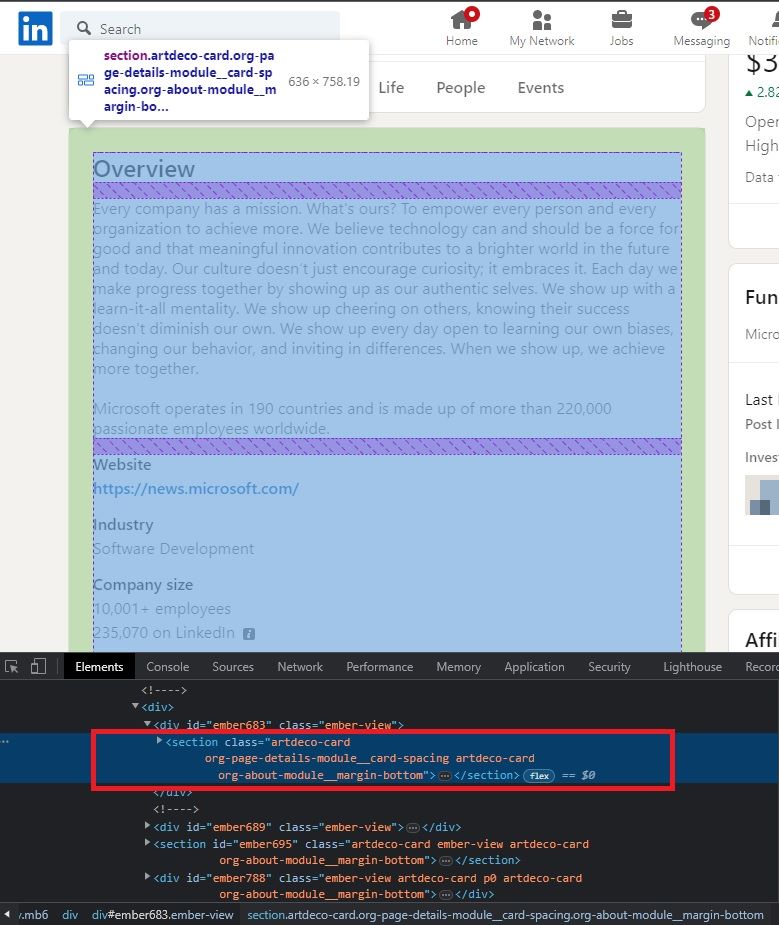
Each of the required fields has similar HTML tags; the only difference lies in their inner texts. For instance, the HTML tag for the website URL is displayed below the image.
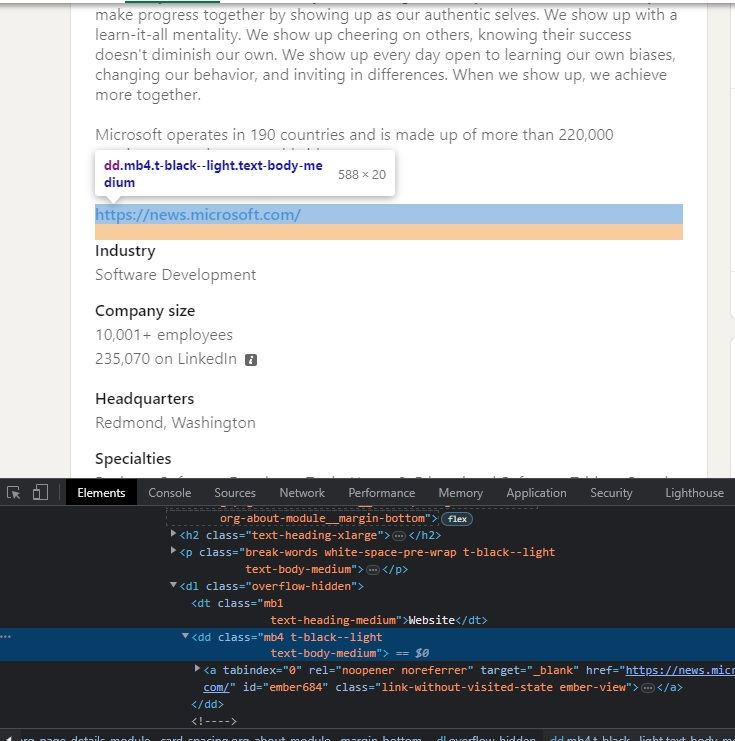
We can use this similarity to extract the desired fields.
To enhance the readability of our code, let’s create a new function called scrape_company(driver, company_url) where the driver is webdriver object and company_url is the URL for the company we want to scrape. The final code within this function will appear as follows:
def scrape_company(driver, company_url):
"""Scrape required fields from LinkedIn Company URL"""
driver.get(company_url + "about/")
company_name = driver.find_element(By.CSS_SELECTOR, "h1 span").get_attribute("innerText")
# Get company about container
about_section = driver.find_element(By.CSS_SELECTOR, "section.org-page-details-module__card-spacing").get_attribute("innerHTML").strip()
about_section = about_section.replace("\n", "")
# Remove extra double spaces
while True:
if about_section.find(" ") > 0:
about_section = about_section.replace(" ", " ")
else:
break
# Scrape Website URL
if about_section.find('Website </dt>') > 0:
company_website = about_section.split('Website </dt>')[1]
company_website = company_website.split('</dd>')[0]
if company_website.find('href="') > 0:
company_website = company_website.split('href="')[1]
company_website = company_website.split('"')[0]
else:
company_website = ""
# Scrape Company Industry
if about_section.find('Industry </dt>') > 0:
company_industry = about_section.split('Industry </dt>')[1]
company_industry = company_industry.split('</dd>')[0]
company_industry = company_industry.split('">')[1].strip()
else:
company_industry = ""
# Scrape Company headquarter
if about_section.find('Headquarters </dt>') > 0:
company_headquarter = about_section.split('Headquarters </dt>')[1]
company_headquarter = company_headquarter.split('</dd>')[0]
company_headquarter = company_headquarter.split('">')[1].strip()
else:
company_headquarter = ""
print("Company Name: {}".format(company_name))
print("Website: {}".format(company_website))
print("Industry: {}".format(company_industry))
print("Headquarter: {}".format(company_headquarter))
6. Scrape data from the job posting page
Scraping the jobs page is as simple as scraping the profile and company pages. In this tutorial, we will extract the job title, company name, and company location, as highlighted in the image below.
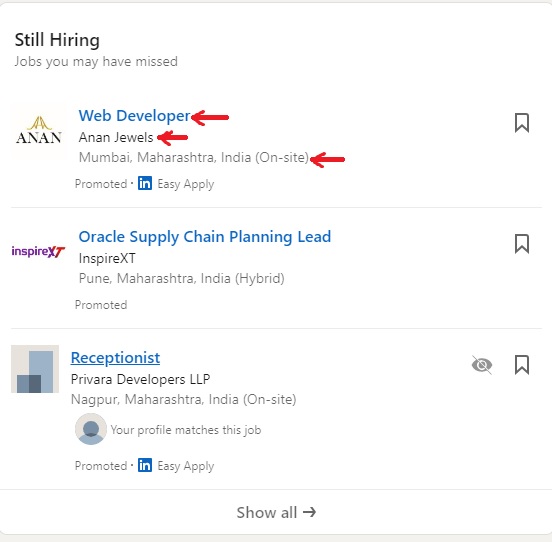
When you inspect these required elements, you will get the following HTML tags:
| Field Name | Field HTML attribute |
|---|---|
| Job Title | <a data-control-id="HJR22e9pOJiRQVKvApmiIw==" tabindex="0" href="/jobs/collections/still-hiring/?currentJobId=3575000774…3D" id="ember925" class="ember-view job-card-container__link job-card-list__title" aria-label="Web Developer">Web Developer</a> |
| Company Name | <span class="job-card-container__primary-description">Anan Jewels</span> |
| Location | <li class="job-card-container__metadata-item "><!---->Mumbai, Maharashtra, India (On-site)<!----> </li> |
Additionally, you may notice that these elements are contained within the main container <ul id="jobs-home-vertical-list__entity-list">. So, our initial step is to locate all <li> items within this <ul> container. The Python code for extracting all the required fields from this container is as follows:
for job in driver.find_elements(By.CSS_SELECTOR, "ul#jobs-home-vertical-list__entity-list li"):
try:
job_title = job.find_element(By.CSS_SELECTOR, "a.job-card-list__title").get_attribute("innerText")
company_name = job.find_element(By.CSS_SELECTOR, "span.job-card-container__primary-description").get_attribute("innerText")
company_location = job.find_element(By.CSS_SELECTOR, "li.job-card-container__metadata-item").get_attribute("innerText")
except:
continue
print("Job title: {}".format(job_title))
print("Company name: {}".format(company_name))
print("Company location: {}".format(company_location))
As you can see, we are using exception handling to skip those elements which don’t have job tags. Again, we will make a function with a name scrape_jobs(driver, jobs_url) and move this code inside this function. The complete function code will look like this.
def scrape_jobs(driver, jobs_url):
"""Scrape required fields from LinkedIn job page"""
driver.get(jobs_url)
for job in driver.find_elements(By.CSS_SELECTOR, "ul#jobs-home-vertical-list__entity-list li"):
try:
job_title = job.find_element(By.CSS_SELECTOR, "a.job-card-list__title").get_attribute("innerText")
company_name = job.find_element(By.CSS_SELECTOR, "span.job-card-container__primary-description").get_attribute("innerText")
company_location = job.find_element(By.CSS_SELECTOR, "li.job-card-container__metadata-item").get_attribute("innerText")
except:
continue
print("Job title: {}".format(job_title))
print("Company name: {}".format(company_name))
print("Company location: {}".format(company_location))
The fully working code for scrapping profiles, companies, and job postings can be found below GitHub URL.
GitHub URL: https://github.com/vilash99/linkedin-scraper-python-selenium
Challenge
Do you want to scale this script even more? Try to scrape more details from the user profile, company page, and job posting page.

