
Scaling scraping projects can be a daunting task as you navigate through large datasets, diverse websites, and evolving technologies.
Whether you’re scraping email addresses, phone numbers, or both, efficient scaling is crucial for project success.
In this blog post, we’ll explore expert tips and strategies to ensure scraping projects are not only accurate and reliable but also scalable.
Table of Contents
- Distributed Scraping with Parallelization
- Use Proxies to Avoid IP Blocks
- Scalable Data Storage Solutions
- Implement Rate Limiting and Throttling
- Handle Dynamic Content with Headless Browsing
- Regularly Update And Maintain Scraping Scripts
- Use Scraping APIs for Large-Scale Projects
1. Distributed Scraping with Parallelization
Distributed scraping with parallelization involves breaking down a scraping task into smaller, independent units and processing them simultaneously to improve efficiency and reduce overall execution time.
This technique is particularly useful when dealing with large datasets or when scraping from multiple sources. In Python, the concurrent.futures module provides a convenient way to implement parallelization. Let’s explore this concept in more detail with examples:
Understanding the Concept
In a traditional, sequential scraping script, each scraping task is executed one after the other. In contrast, parallelization allows multiple tasks to be executed concurrently, leveraging the full capacity of your machine’s resources.
Example 1: Sequential Scraping
import time
import requests
from bs4 import BeautifulSoup
def scrape_blog_title(page_url):
# Scrape page content
page_data = requests.get(page_url).content
soup = BeautifulSoup(page_data, 'lxml')
# Extract Title
blog_title = soup.find('h1', class_='entry-title').text.strip()
print(blog_title)
# Add wait time after each page scrape
time.sleep(2)
websites = ['https://www.vpktechnologies.com/blog/how-to-use-map-filter-and-reduce-functions-in-python/',
'https://www.vpktechnologies.com/blog/what-is-a-dictionary-in-python-and-how-to-use-it/',
'https://www.vpktechnologies.com/blog/how-to-use-context-managers-by-with-in-python/' ]
if __name__ == '__main__':
# Sequential execution
for page_url in websites:
scrape_blog_title(page_url)
In this example, each blog title is scraped sequentially, resulting in a total execution time equal to the sum of the individual scraping times.
Example 2: Parallel Scraping with concurrent.futures
import concurrent.futures
import time
import requests
from bs4 import BeautifulSoup
def scrape_blog_title(page_url):
# Scrape page content
page_data = requests.get(page_url).content
soup = BeautifulSoup(page_data, 'lxml')
# Extract Title
blog_title = soup.find('h1', class_='entry-title').text.strip()
print(blog_title)
# Add wait time after each page scrape
time.sleep(2)
websites = ['https://www.vpktechnologies.com/blog/how-to-use-map-filter-and-reduce-functions-in-python/',
'https://www.vpktechnologies.com/blog/what-is-a-dictionary-in-python-and-how-to-use-it/',
'https://www.vpktechnologies.com/blog/how-to-use-context-managers-by-with-in-python/' ]
if __name__ == '__main__':
# Parallel execution using ThreadPoolExecutor
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(scrape_blog_title, websites)
In this example, the ThreadPoolExecutor from the concurrent.futures module is used to parallelize the scraping tasks. The executor.map() function takes care of distributing the tasks among the available threads, allowing multiple websites to be scraped simultaneously.
Related: How to Build Multi-Threaded Web Scraper in Python
Considerations
- Thread Safety: Ensure that the functions and data structures used in parallelized tasks are thread-safe to avoid race conditions.
- Resource Limitations: Be mindful of resource limitations, as creating too many threads may lead to diminishing returns or even performance degradation.
- Error Handling: Implement proper error handling mechanisms, as exceptions in one thread might not be immediately visible in the main thread.
2. Use Proxies to Avoid IP Blocks
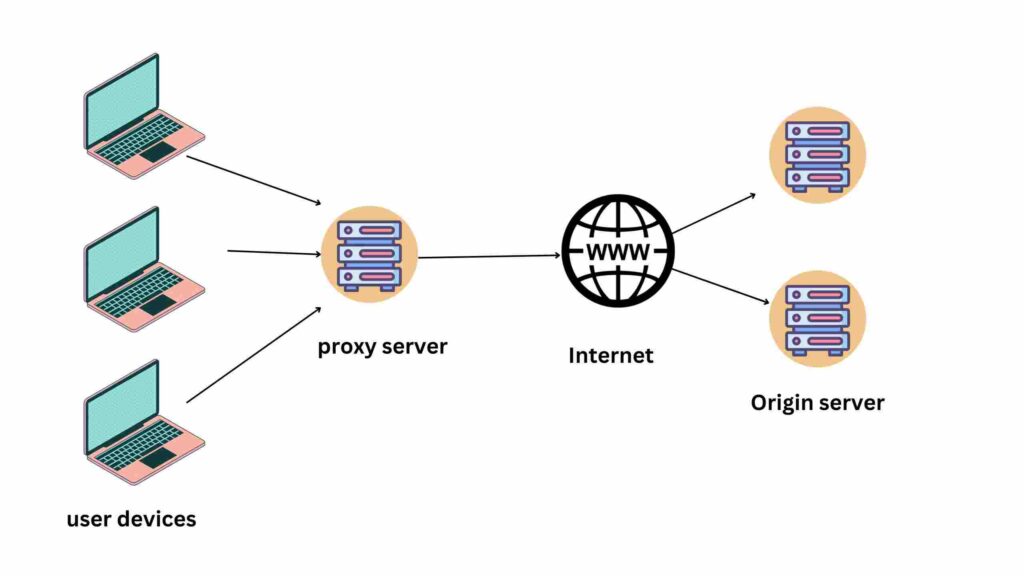
Using proxies to avoid IP blocks is a common strategy in web scraping to prevent websites from detecting and blocking your scraping activities.
Many websites implement IP blocking mechanisms to deter automated scraping and protect their resources. By rotating through a pool of proxies, you can mask your IP address and reduce the risk of being blocked. Let’s delve into this concept in more detail with examples:
Understanding the Concept
When you send requests to a website for scraping, the website can track the source IP address of those requests. If the website detects a high volume of requests coming from a single IP address in a short period, it may interpret this as automated scraping and impose restrictions or block the IP address.
Using proxies involves routing your scraping requests through different IP addresses, making it more challenging for a website to associate all requests with a single source.
Example: Scraping with Proxies in Python
To use proxies in Python, you can leverage libraries like requests along with a proxy provider. For this example, we’ll use the requests library along with a free proxy from ProxyScrape.
import time
import requests
from itertools import cycle
from bs4 import BeautifulSoup
websites = ['https://www.vpktechnologies.com/blog/how-to-use-map-filter-and-reduce-functions-in-python/',
'https://www.vpktechnologies.com/blog/what-is-a-dictionary-in-python-and-how-to-use-it/',
'https://www.vpktechnologies.com/blog/how-to-use-context-managers-by-with-in-python/']
# List of proxy URLs obtained from a proxy provider
proxy_list = [
'http://190.119.76.68:8080',
'http://45.224.148.117:999',
'http://37.32.12.216:4006' ]
# Create an infinite loop of proxies using itertools.cycle
proxy_cycle = cycle(proxy_list)
def scrape_with_proxy(page_url):
# Get the next proxy in the cycle
proxy = next(proxy_cycle)
# Use the proxy in the request
proxies = {'http': proxy, 'https': proxy}
try:
# Scrape page content
page_data = requests.get(page_url, proxies=proxies, timeout=5).content
soup = BeautifulSoup(page_data, "lxml")
# Extract Title
blog_title = soup.find('h1', class_='entry-title').text.strip()
print(blog_title)
except requests.RequestException as e:
print(f'Error scraping {page_url} with proxy {proxy}: {e}')
if __name__ == '__main__':
for url in websites:
scrape_with_proxy(url)
# Adding a delay to avoid rapid requests and reduce detection risk
time.sleep(2)
Considerations
- Proxy Quality: The effectiveness of using proxies depends on the quality and reliability of the proxies. Low-quality proxies may lead to connectivity issues or unreliable IP rotation.
- Proxy Rotation Strategy: Choose an appropriate strategy for proxy rotation. Some applications may benefit from rotating proxies for every request, while others may rotate proxies after a certain number of requests.
- IP Rotation Frequency: Balance the frequency of IP rotation. Too frequent rotation may lead to inconsistencies in session persistence (if applicable), while infrequent rotation may increase the risk of detection.
- Use Proxy Rotation Services: Consider using paid proxy rotation services that manage a pool of high-quality proxies, handle rotation automatically, and provide features such as geolocation targeting.
3. Scalable Data Storage Solutions

Scalable data storage solutions are crucial for handling the large volumes of data generated by web scraping projects, especially when extracting contact information from multiple sources.
These solutions need to be capable of efficiently managing growing datasets and providing quick access to information. Below, we’ll explore the concept of scalable data storage and provide examples using MongoDB, a NoSQL database known for its scalability.
Understanding Scalable Data Storage
Scalable data storage involves the use of systems and databases that can handle increasing amounts of data without sacrificing performance. Traditional relational databases might face challenges when dealing with massive datasets, prompting the need for alternative solutions like NoSQL databases, cloud-based storage, or distributed databases.
Example: Using MongoDB for Scalable Data Storage
MongoDB is a popular NoSQL database that offers horizontal scalability, allowing you to distribute your data across multiple servers or nodes. MongoDB uses a flexible, JSON-like document model, making it well-suited for storing and retrieving unstructured or semi-structured data.
Installation and Setup:
- Install MongoDB on your machine or use a cloud-based MongoDB service.
- Install the pymongo Python driver using the below command:
pip install pymongo
Example: Python Code for MongoDB
import pymongo
# Connect to the MongoDB server (replace 'localhost' and '27017' with your server details)
client = pymongo.MongoClient('mongodb://localhost:27017/')
# Create or access a database
database = client['contact_info_db']
# Create or access a collection (analogous to a table in a relational database)
collection = database['contacts']
# Example data to insert into the collection
contact_data = {
"name": "John Doe",
"email": "john.doe@example.com",
"phone": "123-456-7890",
"source": "example.com"
}
# Insert data into the collection
result = collection.insert_one(contact_data)
print(f"Inserted document with ID: {result.inserted_id}")
4. Implement Rate Limiting and Throttling
Rate limiting and throttling are techniques used to control the frequency and volume of requests made to a web server. These mechanisms are essential in web scraping to prevent overwhelming the server, avoid being blocked, and ensure responsible and respectful interaction with the targeted website.
Let’s delve into these concepts in more detail with examples.
Understanding Rate Limiting and Throttling
- Rate Limiting: Refers to restricting the number of requests a client can make in a given time frame. For example, limiting requests to 10 per second.
- Throttling: Involves controlling the speed at which requests are made. Throttling ensures a consistent and controlled flow of requests over time.
Example 1: Implementing Rate Limiting in Python
import time
import requests
class RateLimiter:
def __init__(self, requests_per_second):
self.requests_per_second = requests_per_second
self.interval = 1 / requests_per_second
self.last_request_time = 0
def wait_for_next_request(self):
current_time = time.time()
elapsed_time = current_time - self.last_request_time
if elapsed_time < self.interval:
sleep_time = self.interval - elapsed_time
time.sleep(sleep_time)
self.last_request_time = time.time()
if __name__ == '__main__':
# Limiting to 2 requests per second
limiter = RateLimiter(requests_per_second=2)
for _ in range(5):
limiter.wait_for_next_request()
response = requests.get('https://www.vpktechnologies.com/')
print(f"Status Code: {response.status_code}")
Considerations:
- Adjustable Rate Limits: Make the rate limits adjustable based on the website’s policies and tolerance for scraping activity.
- Backoff Strategies: Implement backoff strategies in case of rate limit violations. For example, exponential backoff can be applied by gradually increasing the wait time between requests.
- Respecting Robots.txt: Check the website’s robots.txt file for any specified rate limits or scraping guidelines and ensure compliance.
- Monitoring and Logging: Implement monitoring and logging to keep track of request rates and identify potential issues.
Example 2: Implementing Throttling in Python
Throttling can be achieved by setting a fixed delay between consecutive requests. Here’s a simple example:
import time
import requests
# 2 seconds delay between requests
delay_between_requests = 2
for _ in range(5):
time.sleep(delay_between_requests)
response = requests.get('https://www.vpktechnologies.com/')
print(f"Status Code: {response.status_code}")
In this example, a delay of 2 seconds is introduced between each request to https://www.vpktechnologies.com/ , effectively throttling the request rate.
5. Handle Dynamic Content with Headless Browsing
Handling dynamic content with headless browsing is essential in web scraping scenarios where websites heavily rely on JavaScript to load and render content.
Headless browsers, such as Selenium with a web driver, simulate the behavior of a real browser without a graphical user interface, allowing you to interact with and scrape dynamically generated content. Let’s delve into this concept in more detail with examples.
Understanding Dynamic Content and Headless Browsing
- Dynamic Content: Websites often use JavaScript to load content dynamically after the initial page load. This dynamic content may include elements such as images, forms, or text that are not present in the page’s HTML source initially.
- Headless Browsing: A headless browser is a web browser without a graphical user interface. It runs in the background, allowing you to automate browser interactions and navigate web pages programmatically.
Example 1: Handling Dynamic Content with Selenium in Python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
if __name__ == '__main__':
chrome_options = Options()
chrome_options.add_argument('--headless') # Run in headless mode
# Initialize the Chrome browser with headless options
driver = webdriver.Chrome(
service=Service(r'C:\ChromeDriver\chromedriver.exe'),
options=chrome_options)
# Navigate to a page
driver.get('https://www.vpktechnologies.com/blog/how-to-use-map-filter-and-reduce-functions-in-python/')
# Wait forcontent to load (you might need to adjust the wait time)
time.sleep(2)
# Extract Title
blog_title = driver.find_element(By.CLASS_NAME, 'entry-title').get_attribute('innerText')
print(blog_title)
# Close the browser
driver.quit()
Considerations:
- Dynamic Content Detection: Identify the dynamic elements you need to interact with or extract content from. This may involve inspecting the page source or using browser developer tools.
- Waiting Strategies: Implement robust waiting strategies (such as explicit waits) to ensure that your script waits for the dynamic content to be fully loaded before attempting to interact with or extract it.
- Handling AJAX Requests: If the dynamic content is loaded through AJAX requests, you might need to wait for these requests to complete before proceeding.
- Emulating User Interactions: Simulate user interactions, such as scrolling or clicking, if they trigger the loading of dynamic content.
Example 2: Interacting with Dynamic Forms
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
if __name__ == '__main__':
# Initialize the Chrome browser with headless options
driver = webdriver.Chrome(service=Service(r"C:\ChromeDriver\chromedriver.exe"))
# Navigate to a page
driver.get("https://www.vpktechnologies.com/")
# Wait forcontent to load (you might need to adjust the wait time)
time.sleep(2)
# Assume there's a dynamic search form on the page
driver.find_element(By.CLASS_NAME, 'astra-search-icon').click()
time.sleep(1)
search_input = driver.find_element(By.CLASS_NAME, 'search-field')
search_input.send_keys('Web scraping', Keys.RETURN)
time.sleep(2)
# Close the browser
driver.quit()
In this example, we simulate user interaction by entering a search query into a dynamic search form, waiting for the results to load, and then extracting and printing the search results.
Related: How to Install Chrome WebDriver in Selenium Python
6. Regularly Update and Maintain Scraping Scripts

Regularly updating and maintaining your scraping scripts is crucial for ensuring the continued effectiveness and reliability of your web scraping projects.
Websites may undergo changes in structure, layout, or functionality over time, and failing to adapt your scripts accordingly can lead to errors and data inconsistencies.
In this section, we’ll explore the importance of script maintenance and provide examples of how to address common challenges.
Why Regular Updates and Maintenance are Important:
- Website Changes: Websites often undergo updates, redesigns, or changes in HTML structure and CSS classes. If your scraping script relies on specific selectors that have changed, your script may fail to locate elements.
- JavaScript Updates: Dynamic content loaded by JavaScript may change, requiring adjustments to your script to handle new AJAX requests or dynamic element interactions.
- Anti-Scraping Measures: Websites may implement new anti-scraping measures, such as CAPTCHAs or rate limiting. Regularly updating your script allows you to adapt to these measures.
- Improved Efficiency: Script maintenance provides an opportunity to optimize and enhance your code for better performance, readability, and scalability.
7. Use Scraping APIs for Large-Scale Projects
Using scraping APIs (Application Programming Interfaces) can be advantageous for large-scale web scraping projects, especially when dealing with a high volume of data or when you need to streamline the scraping process.
Scraping APIs often provide pre-built solutions, handle scalability challenges, and may offer additional features such as proxy management and data format customization.
Let’s explore this concept in more detail with examples.
Understanding Scraping APIs
A scraping API is an interface that allows developers to interact with a web scraping service programmatically. Instead of writing and maintaining complex scraping scripts, users can make API requests to the service, which handles the scraping and returns the desired data in a structured format.
Example: Using a Hypothetical Email Scraping API
In this example, let’s assume there’s a scraping API that specializes in extracting email addresses from websites. You would typically sign up for an API key and use it to make requests to the API endpoint.
- Step 1: Obtain API Key: Sign up for the scraping API service and obtain an API key.
- Step 2: Make API Requests
import requests
api_key = 'your_api_key'
url_to_scrape = 'https://www.vpktechnologies.com/'
# Make a request to the scraping API
response = requests.get(f'https://api.scrapingapi.com/v1/email-scraping?url={url_to_scrape}&api_key={api_key}')
# Check if the request was successful
if response.status_code == 200:
# Extract email addresses from the API response
emails = response.json().get('emails', [])
print(f"Extracted emails: {emails}")
else:
print(f"API request failed. Status Code: {response.status_code}, Error Message: {response.text}")
Considerations:
- API Rate Limits: Be aware of any rate limits imposed by the scraping API service and adjust your request frequency accordingly.
- Cost Considerations: Understand the pricing model of the scraping API service, especially if it is a paid service. API usage may be subject to certain costs.
- Data Format and Structure: Familiarize yourself with the structure of the API response and customize your script to handle the data accordingly.
Conclusion
Scaling contact information scraping projects requires a strategic approach to overcome challenges related to speed, reliability, and adaptability. By incorporating these tips into your workflow, you’ll be better equipped to handle large-scale scraping projects effectively. Remember to stay informed about web scraping best practices and adhere to ethical and legal considerations to ensure the success and sustainability of your projects. Happy coding!
Image source: Designed by fullvector / Freepik

